「AI观察」关于高效构建Agent:Anthropic说了哪些让海内外AI Agent开发者奉为圭臬的原则?
想知道AI Agent领域的头部公司之一的Anthropic是如何构建高效代理的吗?告别复杂的框架和模糊的概念!这篇深度解读将带你直击核心,快速掌握那些已被海内外开发者奉为圭臬的实用原则。
- 架构的智慧:秒懂“工作流”与“代理”的核心区别,让你在项目开始时就做出正确的技术选型。
- 实用的模式库:获取一套即插即用的架构模式,从简单的提示链到强大的“协调器-工作者”模型,轻松应对各种复杂任务。
- 成功的秘诀:揭秘常被忽视的关键
别再盲目堆砌功能,这篇文章将为你提供一套清晰、简洁且经过验证的构建哲学。点击查看,立即升级你的Agent构建技能!
关于高效构建Agent:Anthropic说了哪些让海内外AI Agent开发者奉为圭臬的原则。
全文章内容比较长,整理大纲如下,看看有没有你感兴趣的话题:
1 | 构建高效的AI代理 |
代理系统的定义
Anthropic定义Agent的时候和Open AI不太一样,Anthropic认为Agent有如下的区别性的特征:
- Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
- Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks. 认为Agent动态地指导自己的流程和工具使用,保持对如何完成任务的控制。
所以如果你的系统基于两个纯问答/处理普通任务的Prompt,那不是Agent,那只是个Chat APP 😂
那么什么时候用/不用Agent呢?Anthropic给出下面几个参考
- 使用Agent
- 允许以延迟和成本为代价换取更好的任务性能 Agentic systems often trade latency and cost for better task performance
- 需要灵活性和模型驱动决策的规模上是更好的选择 when flexibility and model-driven decision-making are needed at scale.
- 使用Workflow
- 工作流为明确定义的任务提供了可预测性和一致性 workflows offer predictability and consistency for well-defined tasks
- 常规的单LLM Prompt调用:Anthropic认为大部分应用结合RAG和在Prompt上下文里面给出几个示例其实就够用了。
LangChain/Graph? 这些AI 框架要不要用?
框架的存在就是为了使得Agent系统更容易搭建。Anthropic很多框架在低级任务上做一些封装(低级任务就是帮你发起LLM API的网络调用、帮助你定义Tool…这些封装就是低级封装),这样的封装带来复杂性。
构建模块与工作流模式
这里Anthropic介绍了几个常见的Agent的系统模式,大概有如下几种
The augmented LLM
The augmented LLM 增强LLM:这个是基础的构建块,在Anthropic眼里,一个最基本的Agent系统构成就是一个能够使用retrieval, tools, and memory能力的LLM,要求模型能够主动检索查询,选择工具。
如何给LLM增强(augmented)呢?Anthropic建议使用MCP
Workflow:
Prompt chaining
将任务拆成流水线,每个LLM Call分别接收上游带来的产物,另外过程中可能会有叫做Gate(门限)的东西去做一些路由/校验。
什么时候选用这模式? 如果你的业务能够轻松干净的拆分出来固定的子任务(task can be easily and cleanly decomposed into fixed subtasks),那就可以用这个模式去套用创建Agent系统。比如生成文档、营销内容。
Routing
在最前面价格分类路由LLM节点,如果业务有明显的分类处理的复杂任务就可以适用这个模式,当然,前面的分类节点也可以采用别的实现,比如传统的AI文本分类算法。
![]()
Routing节点用于将服务引导到下游流程,还有一个值得提倡的点是,如果有简单的任务交付给下游的LLM节点的,我们可以在下游的LLM节点的设置上给他配置一个相对小尺寸低成本的模型。能够更好的均衡整个系统的性能和成本。
Parallelization
并行化,第一段就是由多个节点接收相同数据产出结果之后交给一个聚合结果的节点,结果来自多个LLM节点,适用的场景可以是手动拆分输入之后并行交给LLM处理,这样速度快很多(从调用上虽然增加了,但是LLM是用Token计费的,所以 并发度✕N 并不代表成本 ✕N )
另外,如果你需要多个视角去考虑、审视、处理输入的时候,使用这个模式。因为LLM在处理单角度观点的输出的时候,表现会更加优秀。
还可以这样设计,其中1个LLM我们可以用来设置护栏(Guardrails,之前在Open AI的文章里面也看到这个词了) ,这样也比在同一个Prompt里面去处理会更好,注意力更集中。
除了并行的去处理事情提高速度,我们还可以用来做一些类似投票的事情。举例Code Review的场景,多个不同Prompt的LLM共同参与能发现更多的可能的缺陷,或者是用来审查不良内容,对不良内容进行投票处理。
![]()
Orchestrator-workers
在协调器-工作者工作流中,中央 LLM 动态地分解任务,将它们分配给工作者 LLM,并合成他们的结果。此工作流非常适合无法预测所需子任务的复杂任务。
并行化的描述里面也出现了子任务,那么这个子任务的区别是什么?区别在于,这个子任务是LLM也就是中央LLM节点产出的,不是开发者手动定义的。
这种模式特别适合处理复杂任务,比如跨文件的编码任务,其中一个LLM节点负责编码产出代码,另外一个不断的在循环中评估是否能够满足我们的任务需求。
![]()
The evaluator-optimizer
评估-优化工作流,什么时候使用?当我们有明确的评估标准,并且迭代改进能够提供可衡量的价值时,此工作流特别有效。好的评估标准(比如用户手动提供或者LLM自己提供)能够明显的提升LLM的产出质量。
![]()
在文学翻译、多轮搜索,这种场景特别适合
Agents
LLM在哪些方面能力的成熟,推动了LLM到Agents的进化?→ 理解复杂输入、进行推理和规划、可靠地使用工具以及从错误中恢复understanding complex inputs, engaging in reasoning and planning, using tools reliably, and recovering from error。
Agents适用的场景就是“难以或不可能预测所需步骤数的开放问题”,另外要求用户对LLM的决策有一定的信任度和宽容度。
如果是企业里面的取数或者根据数据做一些业务决策,这种其实对信任度要求就很高,不一定适合Agent
Agents区别于之前的Workflow实现,Agents能够
- 确认计划:在一旦任务明确,代理就会独立计划并操作,可能返回向人类请求进一步的信息或判断。
- 执行并自助获得反馈+上下文:在执行过程中,对于代理来说,在每一步都从环境中获得“真实情况”(例如工具调用结果或代码执行)以评估其进展至关重要。然后,代理可以在检查点或遇到障碍时暂停等待人类反馈。
- 自主停止和确认任务完成:任务通常会在完成时终止,但常见的做法是包括停止条件(如最大迭代次数)以保持控制。
![]()
Agent的成本更高,风险也越高,所以Anthropic建议我们在sandbox环境充分测试,并设置适当的护栏。
Anthropic的在编码场景的Agent建设,为了解决编码问题,引入了很多复杂的Agent能力,比如ComputeUse,从设计上看,有很多亮点。
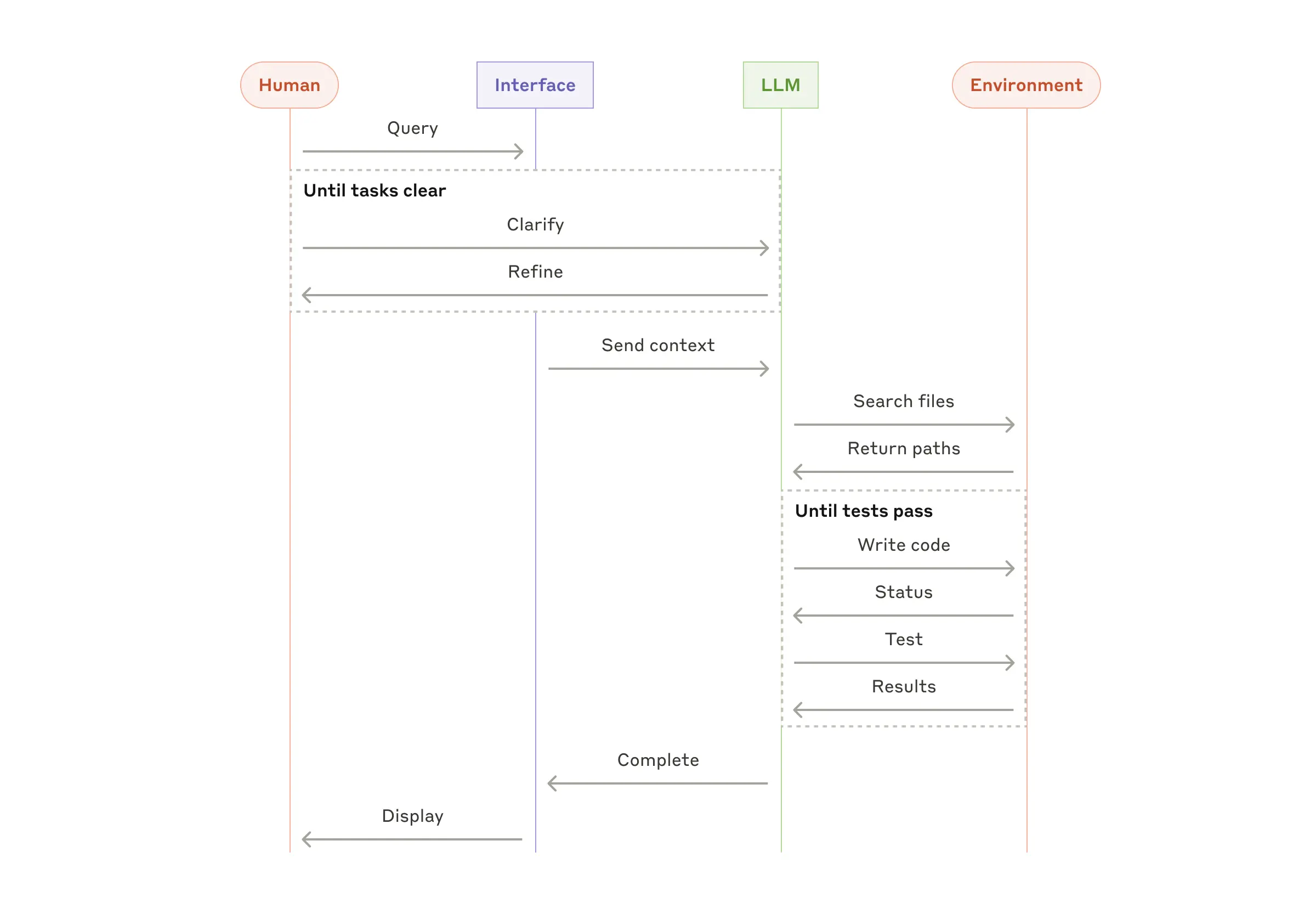
- 先和用户确认澄清,直到任务Clear
- 编码过程中,循环执行写代码、确认状态(比如编译状态,或者联想下 Cursor也会在某个阶段确认IDE Lint状态)、测试、获得结果
总结
Anthropic认为,构建Agent成功的关键在于衡量性能并且迭代实现,没有必要不要增加复杂性。Anthropic始终遵循三大核心原则。
- 在代理设计中保持简洁。
- 通过明确显示代理的规划步骤来优先考虑透明度。
- 通过彻底的工具文档和测试精心打造您的代理-计算机接口 agent-computer interface (ACI) 。
另外还提了一嘴,don’t hesitate to reduce abstraction layers and build with basic components as you move to production. 看来Anthropic对框架的态度还是比较负面的。
附录里面比较有价值的内容
Anthropic认为描述Tool的时候,Put yourself in the model’s shoes,要求我们把自己当做LLM,我们自己能够根据工具的定义清晰的知道根据怎么用,能够实现什么事情。还能知道一些示例用法、边缘情况、输入格式要求以及与其他工具的清晰界限。
Anthropic在处理工具描述上面花了和整体Prompt差不多的时间去打磨优化。
这个在做MCP Server的时候印象特别深刻,成功结果的描述、包括失败的反馈的message对于LLM都有充分的指导意义,LLM能够很快的根据反馈的建议选择继续推进还是完成任务结束。
另外,工具要做防呆机制(Poka-yoke your tool),通过修改参数,让他难以在LLM的驱使下犯下低级错误。
「AI观察」关于高效构建Agent:Anthropic说了哪些让海内外AI Agent开发者奉为圭臬的原则?