AI观察:读Manus的经验总结:是时候关注我们AI产品的Context Engineering建设了
Manus产品组的第一个教训就是围绕KV缓存去成本方面的优化,因为通用Agent(我理解包括deepresearch类型),输入和输出token的差别都非常大,输入的内容Token数量在Manus产品里面,前者可以是后者的100倍。
这里Manus提到了预填充和解码(prefilling and decoding),提到这两个概念的时候,是在讲述Manus在大部分阶段产出的输出往往是结构化的函数调用内容,产出一个JSON结构体来帮助工具调用。预填充阶段可能需要处理大量信息,但是短小的产出,导致解码阶段部分就较为短暂。
两者的意思其实简单来说就是预填充负责初始token的产出,你可以理解人在组织语言的过程。我们在回答别人的问题的时候,往往以“这是一个好问题…”来作为我们的开头,我们可以下意识的说出这句话,并且下意识的脑子里开始浮现一些内容,对AI来说,这部分内容和人类是一样的,产出的速度很快,解码阶段就是随着token的输出,每一个token都影响后面输出内容,这部分就是叫做解码,因为前后要保持连贯的逻辑,所以这部分要比较慢。
在LLM的API售卖价格的时候往往有说明,命中缓存的价格往往是正常价格的1/100。LLM缓存的命中是用前缀来匹配的,有点类似SQL索引命中时候考虑的最左前缀匹配。当前几个token和之前的输入有一致出现的时候,后续的输入就能命中之前的规律计算的结果,直接快速的产出预测token。
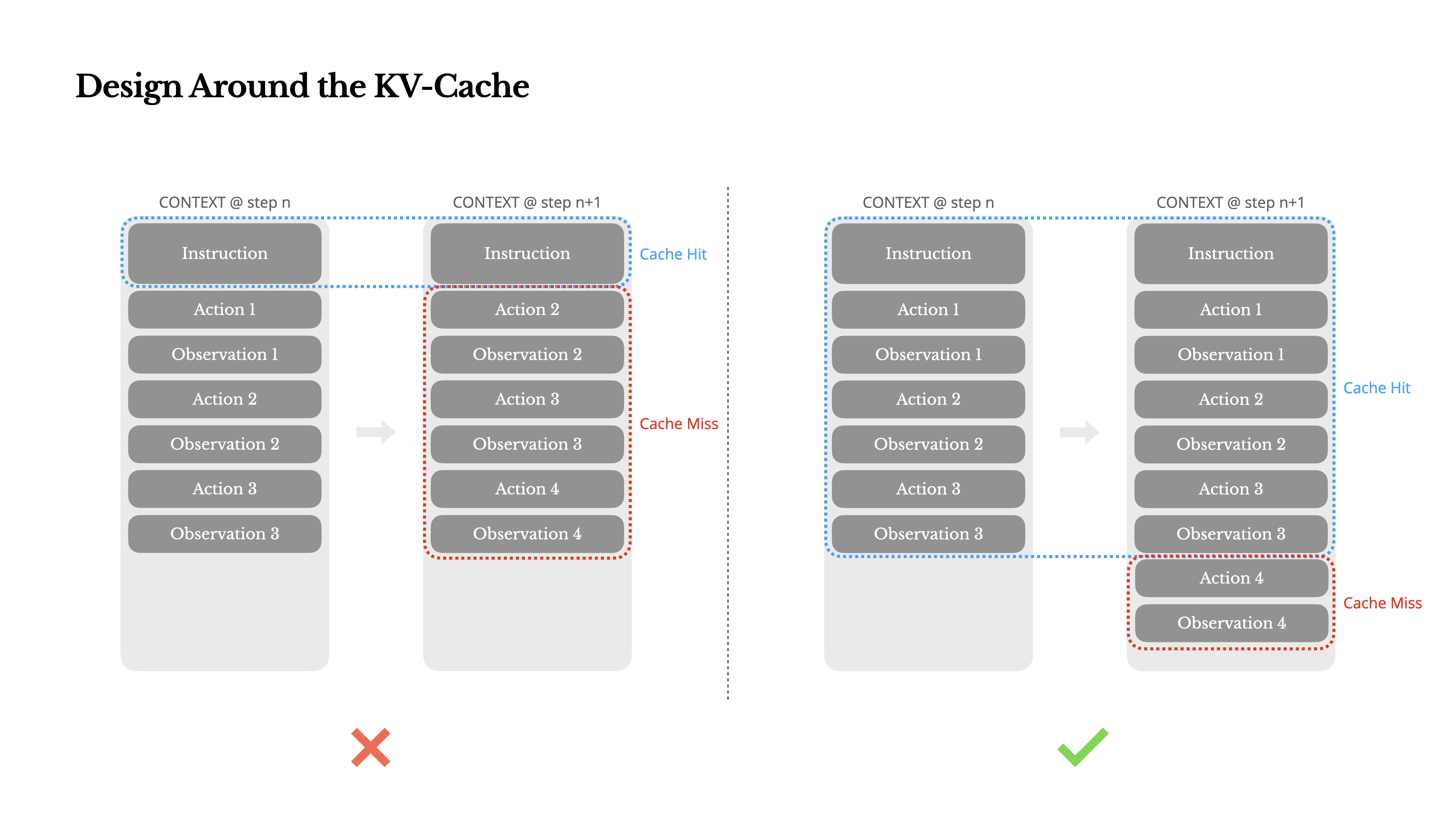
Manus在这张图的左侧说明了,一旦上下文的内容顺序和之前(最左侧,第二个是Action1)的不一致,就不会命中缓存,如果这几次执行的顺序(各类Action的产出喂给大模型的顺序是一致的,就能利用上之前的缓存)。
利用缓存的好处除了能讲成本降下来10倍以外(claude4为例),还能降低响应速度,在LLM应用里面,一般用time-to-first-token (TTFT) 去描述他。
Manus给我们如下建议:
- prompt的前面一部分尽可能保持静态不动,不要在前面加上一些变化的内容,比如时间戳,“你是一个作家,帮我写一个日记,今天是2025-07-23 23:23:49”要比,“今天是2025-07-23 23:23:49,你是一个作家,帮我写一个日记”要好的多,因为前面一部分是每一秒都在变化的。
- 你的上下文应该是追加写的模式,而不是有任何抽取中间部分删除或者修改的操作,我理解就好像在Graph类型的Agent搭建框架里面一样,对于之前的上下文,不停的按照顺序写入,每次交给大模型处理的上下文,如果对之前的上下文有替换,就可能造成一笔不小的开销。想象这里有一个ReAct的流程,每一次都带着上一次的上下文。
- 开发的时候,在prompt里面加上一些 cache breakpoints 的文本
AI观察:读Manus的经验总结:是时候关注我们AI产品的Context Engineering建设了
https://yelihu.github.io/2025/07/21/读Manus的经验总结:是时候关注我们AI产品的Context-Engineering建设了/